|
|
||
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
| philosophi.ca |
|
Main »
Ca STA 2008Conference Report from CaSTA 2008 Note: These notes are are being written during the conference. They are therefore not summative or complete. A deliberate feature of this CaSTA was to give an opportunity for new and incubating projects to present work in progress to get feedback. Thursday, Oct. 16 Meg Twycross: The Virtual Restoration of Altered and Damaged Manuscript, and its implicationsTwycross took us through the digitization and transcription of the York Mystery Plays and the various techniques of forensic analysis. Some of points she made:
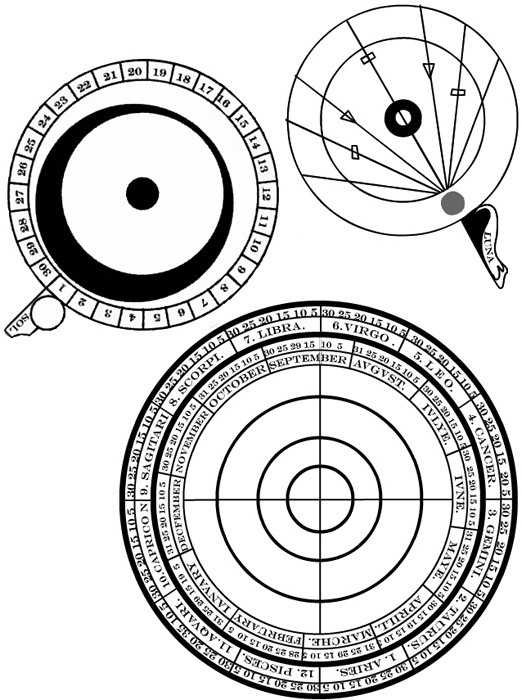
Twycross is not funded, which she takes pride in, and uses Adobe Photoshop. I got a sense of how much time it takes trying these techniques. Funding is always time-limited. Working alone you can take the time to work out all the historical layers in a manuscript, try to date them, and then try to interpret the agendas of the hands. Digitizing Material Culture WorkshopRefining a Digital EditionRichard Cunningham and Harvey Quammen presented on Refining a Digital Edition which discussed issues around a digital edition of the The Arte of Navigation which has Flash supplements that let you play with some of the instruments which were paper dials and things that could be fastened. On thing I like is the provision of images of the paper toys that you can print, cut out and fasten. Is the text best represented as a database or a XML file? Databases and XML structure don't translate cleanly. Harvey discussed how the database allows flexibility in output.
What do you do with metadata from the time?
Marking the Bible Now as Then, or Marking What's Already MarkedPaul H Dyck, David Watt, Stuart Williams presented on Marking the Bible Now as Then. They are working with archival materials at U of Manitoba. The focus of their talk is about how their work on the digital encouraged them to rethink the original materials. Paul showed pages of the Little Gidding Gospel Harmony - these are scrap books that bring parts of the different gospels together, pasted on a page, so you can compare the different accounts. You can read across and see how the different gospels treat the same story. You can, in theory, read a single gospel through David Watt talked about a Psalter Commentary at U of Manitoba. Again these have different orders of reading. Again, even if a psalm is broken up, you can read it through continuously if you skip all the other commentary. He pointed out how the design guides the eye to the different orders of text. The Culture of Curiosity in England, 1560-1660Brent L Nelson talked about The Culture of Curiosity in England, 1560-1660 - a project he is just starting to try to bring together information about curiosity cabinets from the age when there was a shift from literature to "material world that displaced literature as the principal means of higher knowledge in the formative years of the new science." There are three orders of information: Material objects that still survive from collections
Documents to describe collections from letters to full catalogues
Curatorial information collectors wrote about objects in collections
Brent talked about the problems of connecting all the different sorts of information from different sources. He also talked about trying to understand the context of display and approach at the time. How did people approach this? How was it arranged? What can we learn about this shift from humanistic textual information to material collections and how they were used to understand the world. I suggested prototyping in Second Life and Dan O'Donnell recommended trying a game engine. Breaking Ballads: Production, Collection, and The English Broadside Ballad ArchiveKris McAbee discussed a NEH-funded project on Early English Broadside Ballads which is archiving "the over 1,800 ballads in the Samuel Pepys collection". (Abstract here.) They have images of pages and woodcuts and recordings of those ballads for which there is an extant tune. To make the ballads more accessible they have created pages with the transcriptions laid out like the originals. This is a project of the UC Santa Barbara Early Modern Center. The Oldenburg Project: Encoding Texts, Material Production, and Socio-Cultural EnvironmentsLindsay Parker talked about her project on Henry Oldenburg who, while not being an editor, filled an editorial function for the Royal Society. He was, for very little pay, constantly write and translate documents that made texts available. He developed the Philosophical Transactions in 1665. Digitizing Two Rare Seventeenth Century Books: A Digital Research Centre Student ProjectJoel E Salt talked about a project attempting to recreate the layout of books in HTML. They didn't have copyright on the page images but had transcriptions and were trying to find ways to show how the page would have looked. The Roman de la rose in Text and Image: a Multimedia Teaching and Research ToolChristine McWebb and Diane Jakacki presented on the Margot Project at the University of Waterloo. (Abstract here.) MARGOT is a long-term research project devoted to publishing fully searchable editions of either generally inaccessible texts from the French Middle Ages and the Early Modern period (the Ancien R�gime) or of texts in connection with a specific project from the same time period.
They talked in detail about Roman de la rose project within Margot. McWebb has published exerpts with associated information of documents. Her pages have the French and English in parallel with thumbnails of images from different manuscripts. Idols, Icons, and dirtyVR: Material Imagination and Religious ArchitectureStephen Fai talked about religious practice and material imagination (building.) Religious architecture lets you see the relationship between how churches were designed and the practices of the communities that built them. He has identified 9 groups that had built their own churches/temples in Saskatchewan. There is no documentation of heritage building techniques. Fai challenged us on the desire to fully digitize culture. He mentions a Borges story, "On Exactitude in Science", about a country that creates a map that is as complete as the country. If a map (or digital representation) has too much detail (tending toward such depth as to be a simulacra of the original) we will be lost in trivia and lose interest once the complete map is finished. Fai wanted to find a way to represent the synchronicity of wandering around Saskatchewan looking for an Ukrainian Catholic church. For digital collections contextualization is done through navigation - how can one use navigation to simulate. Fair quoted John of Damascus about the difference between idol and icon. The icon is God participating in matter not God herself. I didn't quite get the point; I'm guessing he is trying to understand what he wants to do as creating an icon not an idol. To be honest, I think Fai is really trying to create a useful site for conservators and builders to learn about heritage techniques and materials. Issues in Interpretation: Digitizing Textual And Archaeology Evidence to Reconstructure Jerusalem's Temple MountLisa Snyder presented on the Jerusalem Temple Mount project. (See the Jerusalem Archaeological Park site where you can see low end VR views.) She began by talking about the new Davidson interpretative centre. It was interesting how her work was used for touristic purposes. The project was:
As one can imagine there were contradictions between the documentary evidence and the archaeological evidence. A text would say the columns were marble, but what was found was limestone. This is where the archaeologists had to make decisions. She showed stages of the work including ideas for how to people should look. (They included people in the VR reconstruction to make it more realistic.) While they wanted to provide one unified reconstruction there are spots with switches where users can see alternative reconstructions. These reconstructions raise interesting questions about the relationship between scholarly work and public (in this case museum/interpretative work). I wonder if there is a clear difference and if there is whether that is due to different training/backgrounds of the people doing the work. Friday October 17th We are building it. Will they come?Hoyt N. Duggan of the University of Virginia talked about the Piers Plowman Electronic Archive project. He started by showing the Elwood collation program designed by Eugene Lyman that works over the web. Dugggan commented that experienced editors often don't see different spellings, but software catches such things. Duggan talked about how poorly the Piers Plowman Electronic Archive is selling. Reputable scholarship is not such referencing electronic editions. Could this be that the Plowman Archive is not free but available on CD? (He went CD because it had a material presence and therefore could be considered the equivalent of a print work.) Or, could it be that people are using electronic editions, but not referencing it. This is an important issue - what evidence is there for value? Duggan went on to list the "worms in the apple":
I suspect CD-ROM is part of the problem as it is on the way out and libraries aren't really handling CDs unless they are for the music section. Further people expect online resources to be free or paid for by the Library. The Duggan then showed the way the pages look. It is a clean interface with one nice touch where, as you mouse over the page image on the right you get a red line under the line and the transcribed line on the left gets highlighted. The search system seemed quite powerful, though dependent on regular expressions for complex searches. We had a discussion about regular expressions and whether one can expect people to learn to use them. My sense is that regular expressions are not the way to do as the syntax is too complex to remember if you use it occasionally. Further Google is setting expectations for search, whether we like it or not. By all means provide regular expression support, but provide a simple search interface that is powerful. Schema Harvesting: Conversion of XML Into a Common Form for Text AnalysisBrian L Pytlik Zillig presented on the Abbot schema harvesting system he developed with Steve Ramsay. MONK brings together a variety of e-texts with different XML (and SGLML) markup. Abbot translates these into TEI-Analytics which is a light schema of about 150 elements so all the documents have similar encoding for analytical and mining purposes. A lot of the work is done by an XSLT stylesheet that can handle arbitrary other markup formats. This raises interesting questions:
"I was the least thing there": A Textual Analysis of the Heteronyms of Fernando PessoaHarvey Quamen presented on a project analyzing the work of the Portuguese poet Fernando Pessoa who publishes under different "heteronyms" - or open alternate personas. Pessoa created 3 major heteronyms who were in a world and knew each other. They wrote introductions to each other's poetry. The analytical challenge was to see if there is any residue (style) of Pessoa across the writings of his heteronyms. Quamen showed some of his preliminary results using text analysis techniques like PCA. Quamen also went on to talk about the challenges of the project from issues around what are the authoritative texts to problems with English tools processing Portuguese texts. He also mentioned how the interfaces between programs in a pipelines is a problem. Excel stores stuff internally as UTF-8, but won't bring it in or export it as UTF-8. Ripper: Rich-Prospect Research Browsing for Text CollectionsAlejandro Giacometti presented a team project that is developing a rich-prospect interface for text collections. All the items in a collection are presented as tiles that can be grouped, scaled, and drilled down. It has a faceted feature where you can choose the metadata categories to group by (like author or date) and display. There is a history feature. Tiles provide an affordance that lets one see objects in a collection. Their tiles just have text in them so they have to be read. There is no visual que that could be recognized without reading. Alejandro talked about the history of the design. Ripper has a nice way of keeping the whole collection in view even when you drill into a group. It moves the other tiles down to the bottom of the screen and makes them smaller. One issue is that the text is too small to read. "As soon as there is text users want to be able to read it." Icons don't have that problem. They do have a mouse-over hover feature that pops up more information. Generating Topic-Specific, Individual Knowledge-bases from Internet Resources: REKn Crawler for Professional Reading EnvironmentsRay Siemens presented on the REKu and PReE project. Ray and his team is working with groups like Iter to "scale aspects of our full text model of the professional reading environment". They are also working PKP's OJS to implement social networking features for the Open Journal System. REKn is the text database. PReE is the reading environment. PReE has a three part model, a) representation of texts, b) analytical and critical inquiry perspective, and c) publishing aspect. PReE uses the TAPoR tool interfaces. One challenge they are tackling is how to work with the random stuff available on the web in all its diversity. They have set up a crawler to troll the web grabbing stuff and integrating it into what you get from Iter. They produce "topic specific" collections for reading that gather the Mark data from Iter and stuff gathered by Nutch. I like how they are thinking about starting with Iter and use it to then search the web. Thus you search Iter for "shakespeare sonnets" and the results might suggest more specific patterns to crawl the web. REKn actually offers a number of starting seeds including a text in front of you. I asked Ray about what he thought about shifting from a research project to a production system (that might be hooked into the Scholar's Portal or other library portal). He pointed to the Ithaka report that discusses the problems of moving projects to production. Ray's personal take is that he doesn't want to do production, and I'm with him on this. Building Better Interfaces for Editing and Reading Texts with Multiple VersionsJon Bath talked about a new interface for collating and showed a prototype that he is developing that works through a web interface. Can Text Analysis Be Part of the Reading Field?: The Vision of EvinceAndrew Wade Jewell and Brian Pytlik Zillig presented on the Evince project that tries to address how literary critics are not using powerful text analysis. Most text systems are really for searching and accessing texts. Evince tries to provide access to tools within a site like The Willa Cather Archive. The Evince project is supported by a NEH startup grant. They wanted a visualization tool that avoided rarefied terms and "stands in a immediate relationship to the text in question." They highjack the mouse pointer and tooltip so you get a roll-over square as you mouse over words, mostly dictionary, part-of-speech, and statistical information. You can also get a KWIC that then leads to a version of the text with the key word bolded. This is a brilliant idea. It would be nice to have a generalized version that you can pass a text to and get the interactive version with the mouse over analysis enabled. We had an interesting discussion about whether such tools need to be 100% accurate - especially the POS tagging that gives information. Some felt that having some incorrect information leads to misleading students. I would argue that we have always had inaccurate information in circulation and we all have to learn (and teach) about how to double-check evidence and arguments. Balancing fidelity and functionality: Parallel text representations in a corpus of Mennonite PlautdietschChristopher Cox talked about his Mennonite Plautdietsch linguistic corpus. Linguistic corpora tend to strip out the structural information and they tend to have the language normalized in order to do linguistic analysis easily. Cox talked about large corpora projects like the BNC and then shifted to small minority language corpora like his. Cox showed how the latest version of Omnipage gives an XML output with embedded bounding box information to link back to the image of the page. A problem he faced that is especially true of minority languages, is that there is no single orthographic standard. Spelling varies since there is little formal structures to impose standards. There is a tension between fidelity and functionality. One solution is parallel representations. Slacklining Towards Graduation: Balancing Competing Demands as a Graduate StudentCara Leitch, Jon Bath, and Stan Ruecker gave us perspectives "from the front" to spark discussion about humanities computing and graduate students. Leitch talked about the problem of balancing professionalization activities in humanities computing and finishing the degree. This is a problem not only for students doing digital work - all students are balancing tasks, but computing projects can suck up lots of time without any closure. Grad students are under a lot of pressure to say "yes" to interesting challenges. Cara suggested that supervisors are very important as they can guide the student as to what opportunities to follow and what to let go. There is a fear that if you say "no" then you will be never get asked again - a supervisor can "be the voice of reason." Leitch predicts that there will be an increasing number of graduate students who propose electronic projects as theses which will put pressure on departments to accept these. Jon Bath made the point that the problem of balance is a good one. It is a problem of too many opportunities. The issue is how to finish. Stan talked about creating an environment where the natural thing to do next is what you should do. He also described his methods course and his thesis fest activities. Cara talked about the mystery of graduate school where you don't know what's expected if you didn't have an academic role model in your family. We also talked about completion rates and how many leave bitter. The Future of Text AnalysisDavid Hoover gave the keynote on Friday at the end of the day. David has created a list of departments of English. David started by apologizing for the title. David was focusing on how text analysis and corpus linguistics can offer new kinds of arguments. Some of the points he made were:
I was struck by how David is working back and forth between theories to explain a dendogram (whether well separated or not) and interpretations to the effect that the author wasn't interested in different voices so much as moreal issues or narrative. I wonder how a Bahktinian would respond. They might say that any one character is dialogical and includes different voices - that if an author can switch voices then a character can. It is dialogical (in the sense of a voice including different voices) all the way down.
David uses large numbers of most frequent words (700) as input for MVA. I wonder if the large number is a problem.
David pointed us to Corpus of Contemporary American English (COCOA) that makes freely available a very large corpus online.
Hoover concluded that text analysis doesn't have to prove success on the scale of other "schools" of criticism because we are a small school. I think through the presentation Hoover was subtly trying to show that text analysis works by showing how it can respond to critical claims. Is he answering the observation that text analysis hasn't had an impact by saying it has in his work. Saturday, October 18 Just In Time Research (JiTR): Supporting Experimental Text AnalysisI presented on the JiTR project and related experiments like Now Analyze That. What are they doing over there? Interactive creativity, user generated digital texts and the CEF war diaries transcription groupMark Geldof talked about the limits and interface issues with the War Diaries of the First World War. He contrasted the The Canadian Great War Project which is a social user-edited site. We had an interesting discussion about libraries and social editing (like Wikipedia). Penelope: A Practical Creative Tool for Integrating Authorship, Annotation, Analysis and the Management of IdeasJeff Smith talked about the project he is working on. He showed screens of how his reading environment allows themes to be tagged and an manipulated. His ideas relate to what John Bradley is doing. An important part of the project is providing the ability to mark up (overlapping) interpretation for later analysis on the fly. At a deeper level he is imagining the design of the underlying structure behind creative work. I can imagine that some people might think of their creative writing as the implementation of structure, but for others there is no underlying structure. Stand-Off Markup PanelThere was an interesting panel on stand-off markup. Justin gave an interesting demo of stand-off markup and commented that HTML image-maps, CSS, and book indexes, are examples. What do we lose if we separate out the encoding? I think stand-off markup is a great idea without tools that can be used by most people. In particular we need something like that for interpretative purposes. I'm worried that trying to use stand-off adds a misdirection that means another level of processing and another level of abstraction which makes it harder to understand and harder to Jeff Smith distinguished "assembly" stand-off from other types of stand-off. Dan O'Donnell argued that XSLT is stand-off and an adequate tool. |
Navigate |
| Page last modified on October 25, 2008, at 01:07 PM - Powered by PmWiki |
{kind=link}